Part 2 of a four-part series on cyber resilience in the mining and metals industry Read Part 1 here.
In the December/January issue, I discussed transitioning from cybersecurity-based approaches to protect operations towards a more holistic cyber resilience approach. While cybersecurity relies on deploying security controls to protect critical systems and technology, cyber resilience focuses on business objectives and how an organization can ensure those objectives are met.
Effective cyber resilience consists of three critical domains of equal weighting: operational resilience, resilient cybersecurity and resilient cyber communications. This article will dig deeper into operational resilience and how mining organizations can build more resilient operations.
An overview of operational resilience
While there are many potential causes of crucial technology and system outages, cyber resilience focuses on reducing the impact of those outages on production, ensuring continued operations for the time necessary to restore those services. As operations rely more on technology for basic operations, work to ensure operational resilience becomes even more critical.
Planning is a prerequisite for building cyber resilience. From the inventory of all systems and technology used, the “heartbeat” systems—those systems and technology without which operations cannot continue—must be identified. Disaster recovery and business continuity plans must be completed for the critical applications, network components and infrastructure that support the heartbeat systems.
Disaster recovery plans (DRPs) contain the processes necessary to restore systems to a functional state. Most importantly for cyber resilience planning, the DRPs must contain recovery time objectives (RTOs) indicating how long technology teams will take to restore the systems.
In contrast with DRPs, business continuity plans (BCPs) are focused on the business processes and how they can continue without those critical technology systems. The BCP documents the processes necessary to continue that critical business function without the technology. MM-ISAC defines a resilient operation as one where the BCP allows business to continue 50 per cent longer than the expected time to recover from technology and systems outages.
Of course, both these sets of plans must be continually tested, rehearsed and updated to ensure that all key teams involved in both business continuity and disaster recovery know their roles and so that performance assumptions in those plans continue to be accurate over time.
A simplified case study
To illustrate how an operation can establish and maintain operational resilience, let’s look at one function in a typical mine: haulage. For this example, let us assume a traditional open-pit operation, utilizing a fleet of haul trucks moving material from the pit to the plant for processing. In order to safely co-ordinate the movement and assignment of those haul trucks, the operation has deployed a computer-based dispatch system used by the mine dispatchers to track the location of trucks, assign trucks to their destination and resolve any routing conflicts that will impact the efficiency of the haulage operation, providing guidance and directions to the operators through their in-cab computers connected to the mine’s wireless network.
To establish resilience, the heartbeat technology must be identified, and DRPs must be developed to guide the restoration of those systems. In this case, the heartbeat systems and their RTOs are identified as:
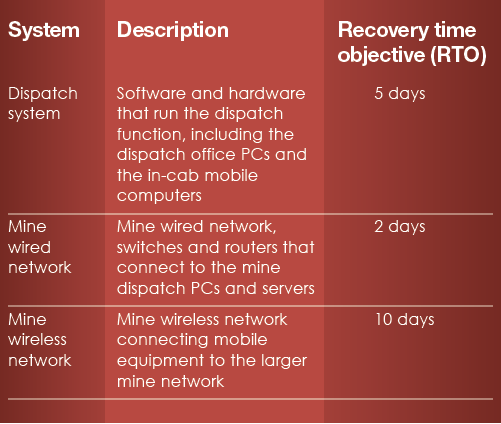
To ensure the mine haulage function is operationally resilient, the BCP developed is a set of processes and procedures to manually dispatch vehicles, utilizing radio communications with dispatchers, for 15 days. To validate this plan, a tabletop exercise is conducted, followed by a live test over the course of one shift. This test identifies that, while operations can continue in this manual mode, there is a 15 per cent loss in efficiency. The operation leadership views that loss as acceptable for a maximum of 15 days and signs off on the plan.
Losing resilience through new technology
Fast forward to the future, and in this case study this operation has decided to deploy an autonomous haulage system (AHS) to replace the fleet of operator-driven haulage vehicles. The deployment of the new AHS will replace the dispatch system, resulting in a change to the list of heartbeat systems as follows:
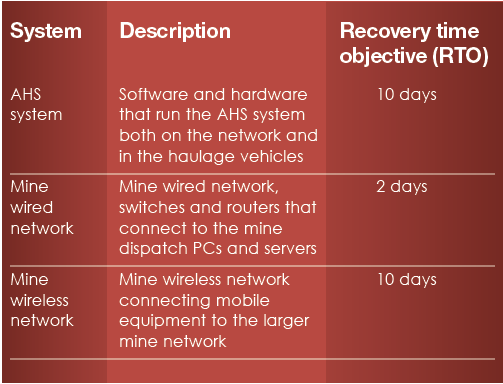
Notice that due to the increased complexity of the AHS system over the previous dispatch system, the recovery time to restore functionality has increased to 10 days. In developing a BCP to cover the 15 days necessary, the operation hits a snag. While the existing manual dispatch procedures would remain effective, there is no possible solution to staff all the trucks with drivers. The best-case scenario would have only 15 per cent of the trucks manned with qualified, current drivers who can safely operate the trucks. This would lead to a loss of 85 per cent in haulage efficiency for the 15 days. That level of mine performance would result in the plant being starved for input and a plant shutdown. Operation management identifies that the site can only absorb an 85 per cent loss of mine productivity for one day before production must stop—the operation is no longer resilient.
This scenario illustrates the challenges operations face as they deploy new technology; be it automation in the mine or machine learning and artificial intelligence in the plant, often, resilience is lost.
To restore resilience in this scenario, the operation must reach a point where the plant will no longer be starved for input material should an outage occur. A full process view of cyber resilience will help the operation solve this issue. Teams at the site propose solutions to the problem:
Technology team: Deploy fully redundant systems for the AHS, wired and wireless systems. This will include developing a complete “warm standby” system that can be activated in the case of a failure, stocking critical spares for all network equipment for immediate replacement and ensuring that the necessary technical capabilities are always available on short notice. This will reduce the RTO for all systems to less than 24 hours. However, the cost will be significant, nearly doubling the operational expenses of the AHS system.
Mine operations: Ensure sufficient trained drivers at the site to operate the haulage fleet in case of an AHS outage by cross-training staff as haul truck operators. This, however, poses other challenges: first, there is a cost to train and maintain skills in that group of operators, and testing shows that if deployed, their lack of practice will result in an increased efficiency hit. In addition, union contracts do not currently allow union staff to be used this way, so an agreement with labour unions will need to be secured.
Plant team: Increase the ore stockpile from one day to 15 days to maintain plant operations while the AHS systems are recovered. This solution will require sufficient space for the stockpiles and a further increase in mining rates to establish that stockpile.
In isolation, each of these solutions to re-establish resilience is costly and potentially disruptive to the operation. By taking an overall view of the business process, the operation can combine lower cost options to achieve resilience. For example, the operation can implement a handful of lower-cost, high-value redundancy options that reduce the RTO from 10 days to six, thus reducing the period that needs to be covered by the BCP to nine days. To ensure the plant has sufficient feedstock for that period, the site decided to take advantage of an upcoming maintenance shutdown at the plant to build a stockpile to buffer any AHS outage.
By taking a full business process view of resilience, operations can protect themselves from all types of outages. This is a more effective and easier-to-manage approach than the traditional approaches of applying excessive cyber controls to cover cyber risk, redundancy to take care of technology risk and separate business process changes for other risks. Rather than focusing on individual risks and domains, the operation eliminates the impact of the outage by focusing on the result—in this case, maintaining ore supply at the plant.
In the March/April issue, I will focus on resilient cybersecurity.
Rob Labbé is the CEO and CISO (chief information security officer)-in-Residence at MM-ISAC.



